NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2019.10.15
438
今回は、膨大なデータの数を高速で集計したり、検索できるように作成されたNHNの「データマート(Data Mart)」について紹介します。
従来の高速集計で最も多く導入される方法は、OLAP環境のデータキューブ(Data Cube)です。
データの構造を次元(属性、ディメンション)で設計し、これに必要な値(測定値、数量)をあらかじめ計算しておく方法です。(あらかじめ計算せずに関係のみを設定しておいた状態で、照会時にキューブが生成されるリレーショナルOLAPもありますが、今回は速度について論じるので除外します。)
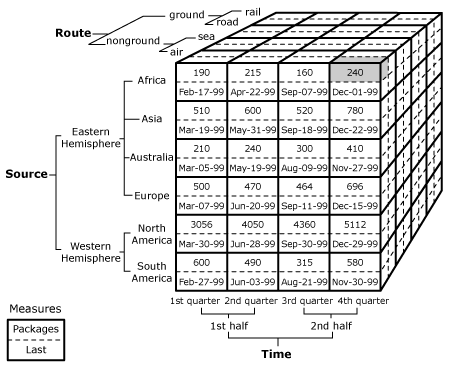
データキューブを簡単に説明すると
select country, count(population) as population_of_nation from nation_table group by 1
の結果値(国の人口)をあらかじめ作成しておく一種のインデックスあるいはキャッシュと言えます。
また、
select country, state, count(population) as population_of_state from nation_table group by 1, 2
の結果値(各国の州の人口)も事前に計算して配置します。
このように必要なすべてのケースの数をあらかじめ計算しておけばよいのですが、属性が多くなるほど、計算量が多くなり、保存しなければならない空間も大きくなってしまいます。
そのため、すぐに集計するために作成したキューブでさえ、最終的には遅くなるという悪循環が繰り返されます。
また、州(state)単位の数値を見ていれば、おのずと市(city)単位の数値も見たくなるでしょう。(ドリルダウン)
さて、ここでは州単位まで計算しておきました。キューブを分割する瞬間です。
高速計算するために作られた「ひとまとまりのテーブル」をさらに分割して、分割したものをJOIN式に回帰しなければなりません。
「なぜOLAPで構築したのか?」と途方にくれることでしょう。
そこで、このように考えてみました。
「どうせ分割するなら、あらかじめバラバラにして分けたものを別に(高速)集計してみよう!」
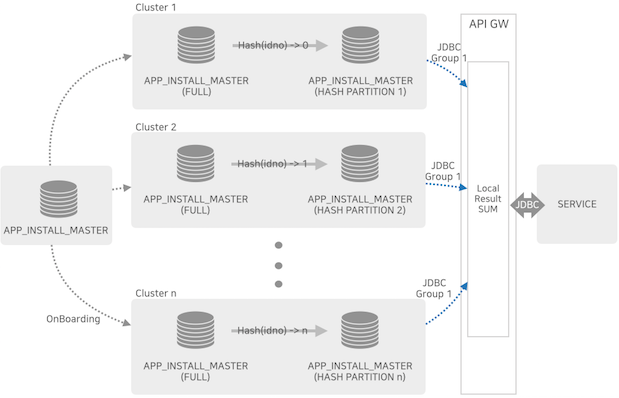
ボディが大きいデータをキー基盤のパーティションに分け、これを複数のクラスタに分割する形態です。このクラスタの計算結果が中央のコンピューティングゲートウェイに集中して最終的な結果を出力、伝達します。
図のように、各クラスタとのインターフェースはJDBCで、クラスタでなくてもJDBCスペックに対応するすべてのデータベースが連動できます。API ゲートウェイ(API GW )とサービスのインターフェースもJDBCのため、これを使用しているサービスはすぐに適用することができます。
また、細かく分割しているので、テーブルをキューブやダイスにする必要がなく、そのまま正規化しておき、結合(join)して使用しても問題ありません。
このような構造を利用して、65台程度のデータノードを持つ社内共通クラスタ(CDP Common Data Platform)で10秒以上かかる非常に重い3億件の多重結合クエリを、4台構成したクラスタの4連合(全16台)で3秒台まで減らすことができました。
データを使うサービスは、データがどのように構成されているか把握する必要はありません。ユーザーのリクエストに応じて表示するデータをコントロールできるようにあらかじめポリシーを構成しておくことが重要です。
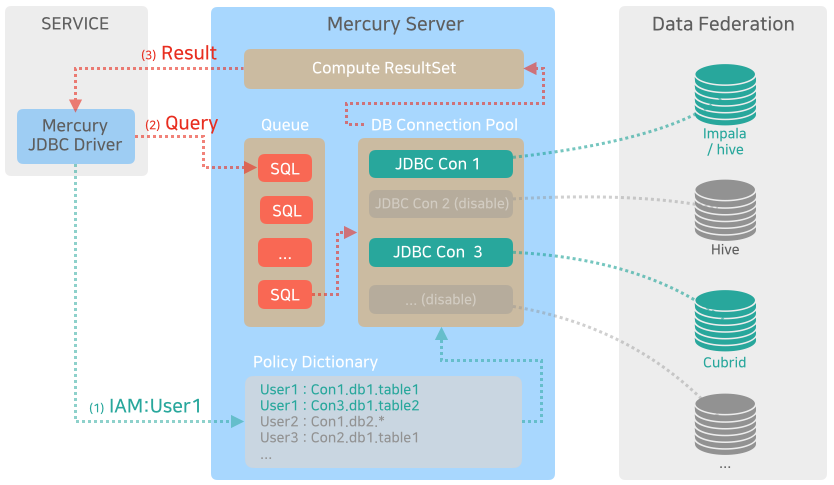
このように作っておくと、次のようなシナリオも追加できます。
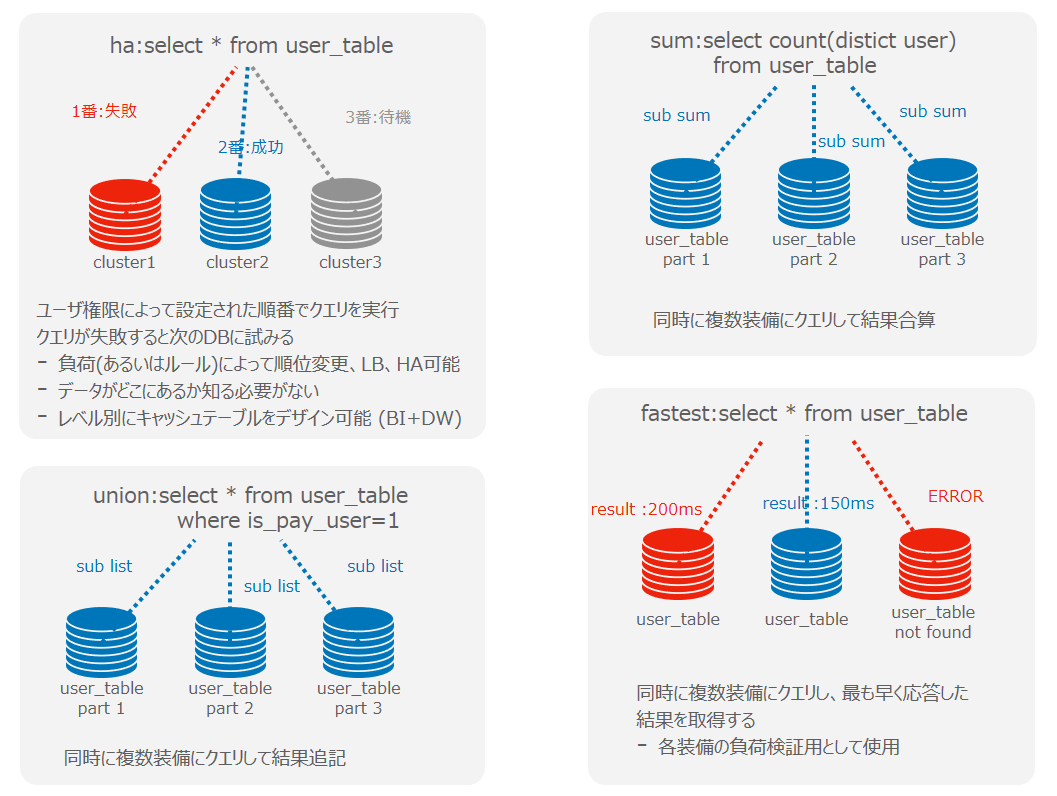
接続可能なサーバーに優先順位を置いて照会し、成功するまで巡回する構造です。
1番目の装備に障害が発生すると、2番目に照会し、自動的にHAを実現することができます。
また、巡回するので、ユーザーはどのデータベースに希望するテーブルが存在するか知る必要がありません。
優先順位も照会時点で決定できるため、接続数に余裕のある順にクエリを要請でき、負荷分散も可能です。
指定されたすべての接続先サーバーに対し同時照会し、出力された結果をまとめて配信する仕組みです。
キー別にデータが分散されているので、個別処理も可能で、各接続先サーバーが担当するデータが少なくなるため、台数が増えるほど速い処理速度を見せます。
指定されたすべての接続先サーバーに同時照会した後、最初に回答を得られたデータを採用する構造です。
HAモードで、あまり忙しくない接続先サーバーを検索するときに使用しています。
このようなソリューションは、探してみると色々あります。
代表的なものとして、Presto、ProxySQLなどがありますね。
しかし、処理待ちデータ(キュー)、データのカプセル化、ユーザーポリシーなど、われわれの「ビジネス事情」を適用しようとすると、適切なソリューションが見つからなかったので、自分たちで実装しました。
その代わり、JDBCを利用しているため、いつでもこのような柔軟な接続先設定とデータ連携を実装できる構造になっています。


NHN Cloud Meetup 編集部