NHN Cloud Meetup 編集部
NHN Cloudの技術ナレッジやお得なイベント情報を発信していきます
2020.04.02
6,895
Redisは、REmote DIctionary Serverを略したものです。おそらくこの記事を読まれているほとんどの方は、Redisを使用したり聞いたりしたことがあることでしょう。

Redisはオープンソースなので、さまざまなサービスで自由に使用されています。上図からもわかるように、Airbnb、Uber、InstagramでもRedisが使用されています。TOAST File、Doorayなど、NHNの社内でも多くのチームがRedisを使用しています。昨年、Coupangで大きな障害がありましたが、その原因はRedisであることが明らかになりました。
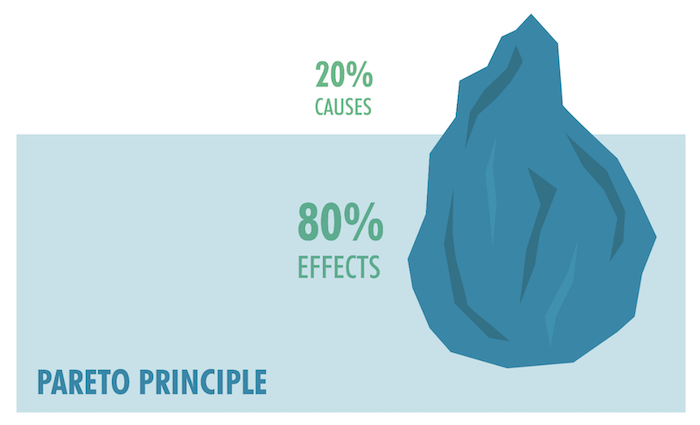
ところで、パレートの法則をご存知ですか?私たちの社会で起こる現象の80%は20%の原因によって発生している、ということを意味する法則です。ウェブサイトへのアクセスもパレートの法則が当てはまり、インターネット通信の80%は、わずか20%のサイトに対するアクセスであると推定され、この20%のウェブサイトのデータをキャッシュしておくと劇的に効率を向上させることができると言われています。(インフラエンジニアの教科書-ネットワーク編, 2017)したがって、共通して使用されるデータは、Redisを用いてキャッシュに保存しておくと、リソースを効率的に利用できます。
Redisはインメモリデータベースです。つまり、すべてのデータをメモリに保存して照会します。従来のリレーショナルデータベース(Oracle、MySQL)よりもはるかに速い理由は、メモリアクセスがディスクアクセスよりも速いからです。しかし、速さはRedisの特徴のうちの一部分です。ほかのインメモリデータベース(ex. Memcached)との最大の違いは、さまざまなデータ構造をサポートするという点でしょう。Redisは以下のようにさまざまなデータ構造をKey-Value形式で保存します。
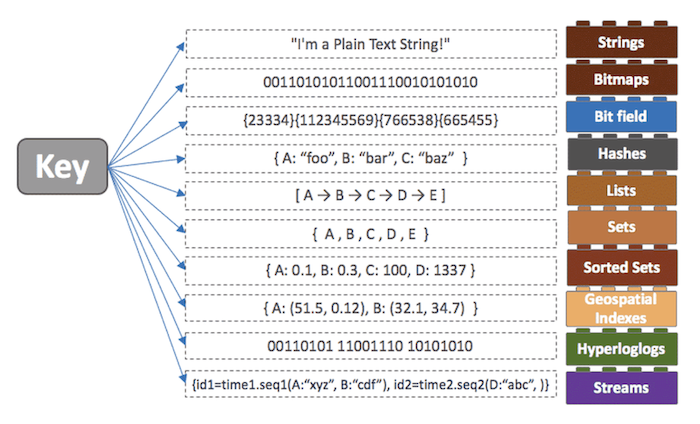
Redisは基本的にString、Bitmap、Hash、List、Set、Sorted Setを提供し、バージョンがアップするにつれ現在ではGeospatial Index、HyperLogLog、Streamなどのデータ型にも対応しています。
それでは、このようにさまざまなデータ構造を提供することがなぜ重要なのでしょうか?
それは、開発の利便性と難易度のためです。
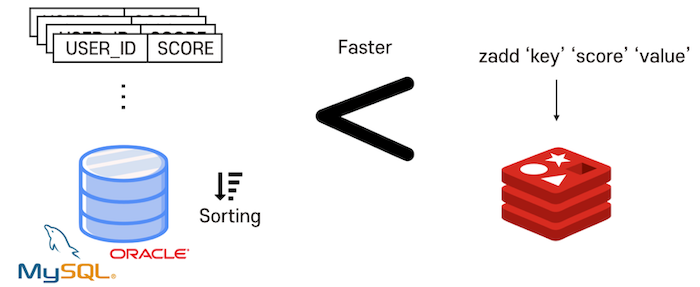
たとえば、リアルタイムランキングサーバーを実装する際にリレーショナルDBMSを利用した場合は、DBにデータを保存したり、保存されたスコア値で並べ替え再読み込みするプロセスが必要になります。数が多くなると速度が遅くなるのは、この過程でディスクを使用するためです。インメモリ基盤でサーバーからデータを処理するように直接コードを組むこともできますが、RedisのSorted Set(ソート済みセット)を利用した方が、より速く、より簡単に実装できます。
 Redisはトランザクションの問題も解決してくれます。シングルスレッドで動作するサーバーのすべてのデータ構造はアトミックであるため、競合状態(race condition)を回避してデータの整合性を確保しやすくします。
Redisはトランザクションの問題も解決してくれます。シングルスレッドで動作するサーバーのすべてのデータ構造はアトミックであるため、競合状態(race condition)を回避してデータの整合性を確保しやすくします。
つまり、外部のCollectionsをうまく利用するだけで、開発時間を短縮することができ、想定していなかったさまざまな問題を解決できるため、開発者はビジネスロジックに集中できるという大きなメリットが存在します。
それでは次に、現在Redisで提供されているデータ構造について調べてみましょう。
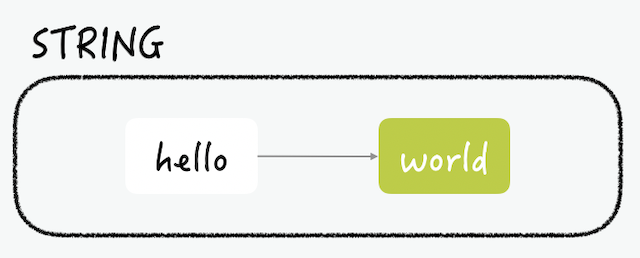
RedisのStringは、キーと接続できる最も簡単な型の値です。Redisのキーが文字列であるため、この構造は文字列を別の文字列にマッピングするものだとわかります。
> set hello world OK > get hello "world"
String型には、すべての種類の文字列(バイナリデータを含む)を保存することができます。したがって、JPEG画像を保存したり、HTMLフラグメントをキャッシュする用途としてよく使用されます。保存できる最大サイズは512MBです。Stringは最も基本的なデータ構造で、次のようにさまざまな機能を提供しています。
> set counter 100 OK > incr counter (integer) 101 > incr counter (integer) 102 > incrby counter 50 (integer) 152
> INCR mycounter (integer) 1 > GETSET mycounter "0" "1" redis> GET mycounter "0"
> set mykey newval nx (nil) > set mykey newval xx OK
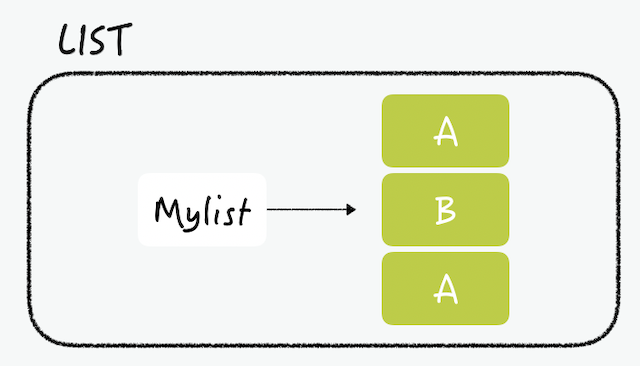
RedisのListは、一般的な連結リスト(linked list)の特徴を持っています。したがってリスト内に何百万個のアイテムがあってもheadとtailの値を追加すると、同じ時間がかかります。特定の値またはインデックスでデータを検索したり、削除することができます。
LPUSH mylist B # now the list is "B" LPUSH mylist A # now the list is “A","B" RPUSH mylist A # now the list is “A”,”B","A"
Listはさまざまなタスクに役立てられますが、代表的な使用例に、Pub-Sub(出版購読型モデル)のパターンがあります。プロセス間の通信方法で、出版者がアイテムを作成してリストに入れると、購読者が取り出してアクションを実行するといった具合に動作します。Redisはこれを効率的かつ安定的に行うことができます。
Twitterでは、各ユーザーのタイムラインにツイートを表示すために、RedisのListを使用します。
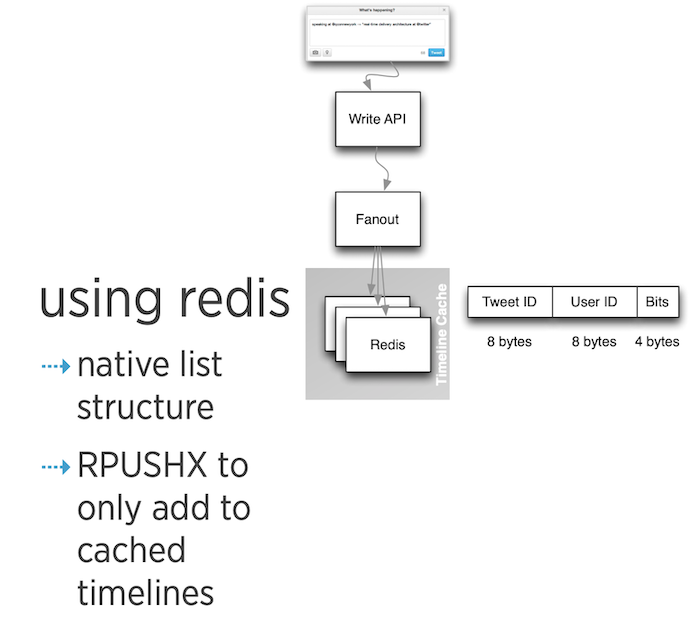
ここで使用した RPUSHXキーは、キーがすでに存在する場合にのみデータを保存するため、これを利用してすでにキャッシュされた(すでにキーが存在する)タイムラインのみのデータを追加することができます。詳しい適用方法は、(リンク)から確認できます。
また、一時的にListを遮断する機能も有効活用できます。Pub-Sub状況ではリストが空になったときにpopしようとすると、通常はNULLを返します。この場合、出版者は一定時間待機してから、もう一度popしようとします(= ポーリング/polling)。RedisのBRPOPを使うと、新しいアイテムがリストに追加されるときにのみ応答するので、不要なポーリングプロセスを減らすことができます。
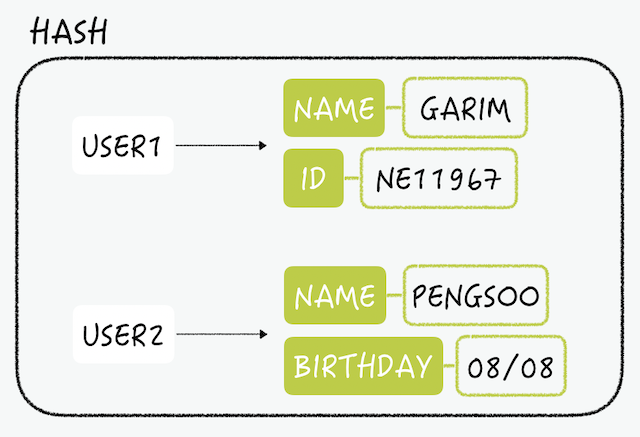
Hashはfield-valueのペアを使用した一般的なハッシュです。キーのフィールド数には制限がないので、さまざまな方法で使用することができます。
フィールドとバリューで構成されるという面から、HashはRDBのテーブルと似ています。ハッシュキーはテーブルの主キー(primary key)、フィールドはカラム、バリューはバリューと見做すことができます。キーが主キーのような役割をするため、1つのキーはテーブルのロー(行)と同じです。以下は、一般的に使用されるRDBのテーブルをRedisのハッシュ構造で表した図です。
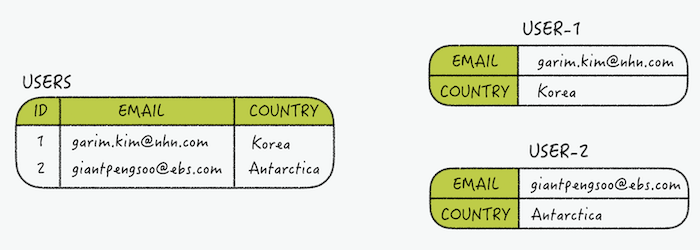
> hmget user-2 email country 1) "giantpengsoo@ebs.com" 2) "Antarctica"
下記のように、個々のアイテムをアトミックで操作できるコマンドもあります。
> hincrby user:1000 birthyear 10 (integer) 1987 > hincrby user:1000 birthyear 10 (integer) 1997
Setはソートされていない文字列のコレクションです。一般的なSetがそうであるのように、アイテムは重複できません。積、和、差集合演算をRedisで実行できるので、Setはオブジェクト間の関係を表現するときに便利です。
Setを利用したタグの機能を例にあげてみましょう。Doorayプロジェクトにタグを指定すると、IDが1000であるプロジェクトに1,2,5,77番のタグIDが接続されている場合、Setでこの関係を表現する方法は簡単です。キーの値をproject:1000:tagsとして指定して、ここにすべてのタグをaddしてくればよいのです。(キーは常に直感的なものをお勧めします。プロジェクト- > ID 1000- >タグ)
> sadd project:1000:tags 1 2 5 77 (integer) 4 > smembers project:1000:tags 1. 5 2. 1 3. 77 4. 2
あるいは、以下のようにタグを基準に保存することもできます(タグ- > ID 1を所持- >プロジェクト)。1,2,10,27タグを持っているすべてのプロジェクトのリストを希望するときは、SINTERコマンドで簡単に確認できます。
> sadd tag:1:projects 1000 (integer) 1 > sadd tag:2:projects 1000 (integer) 1 > sadd tag:5:projects 1000 (integer) 1 > sadd tag:77:projects 1000 (integer) 1 > sinter tag:1:projects tag:2:projects tag:10:projects tag:27:projects 0) 1000 ...
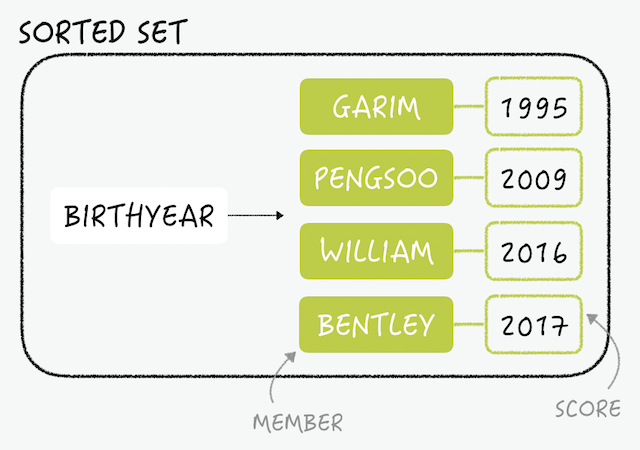
Sorted Set(ソート済みセット)はSetと同様に1つのキーに重複していない複数のメンバーを保存しますが、それぞれのメンバーはスコアで接続されます。すべてのデータは、この値でソートされ、スコアが同じであれば、メンバー値の順にソートされます。Sorted Setは、主にソートが必要なところに使用されます。
Sorted Setはソートされた形で保存されるので、インデックスを利用して素早く照会できます。(インデックスを利用して照会することが多い場合は、ListよりもSorted Setを推奨します。)
> zrange birthyear 2 3 2) "WILLIAM" 3) "BENTLEY"
スコアを利用した照会ももちろん可能です。上記のサンプルの場合、メンバー値は名前、スコアは生まれた年です。たとえば、2000年代のすべてのメンバーを照会したいときには、次のようにZRANGEBYSCOREコマンドを使って2000年から〜まで(+inf)で検索できます。
> zrangebyscore birthyear 2000 +inf 1) "PENGSOO" 2) "WILLIAM" 3) "BENTLEY"
今まではキーにマッピングされているデータ構造について紹介しましたが、これからはRedisのキー自体について考えてみましょう。
Redisのキーは文字列であるため「abc」からJPEGファイルまでのすべてのバイナリシーケンスをキーとして使用できます。空の文字列もキーになることがあります。String型と同様に許容される最大キーサイズは512MBです。
キーを照会するときのコストを考えると、長過ぎるキーはお勧めしません。もし、そのようキーを保存する必要がある場合は、むしろHashのメンバーとして保存した方がよいでしょう。とはいえ可読性のよい「user:1000:followers」を「u1000flw」に減らしてはあまり意味がありません。
Redisのキーをうまく設計することも重要です。どのようにキーを生成するかによって分散が集中したり、これを回避することができます。通常のスキーマを使ってRedisのキーを設計するのがよいでしょう。たとえば「user:1000」のようにobject-type:idの形式をお勧めします。「comment:reply.to」または「comment:reply-to」のように.,–,:などの符号を使って関係を表現できます。
キーのコマンドは、データ型に限らず使用することができます。SORTは入力されたキーに該当するアイテムをソートして表示します。List、Set、Sorted Setに使用でき、特にソートされていない状態で保存されたSetを当該コマンドを使ってソートさせて表示することができます。EXISTSコマンドは当該キーがRedisにあるかを確認し、DELコマンドは値に関係なくキーを削除します。TYPEコマンドは当該キーに連結されたデータ構造がどのような形態であるかを返します。
キーと関連して重要な機能であるExpireについてもみてみましょう。Redisはインメモリデータベースのためメモリに格納できるデータは限定的です。これ以上メモリにデータを保存できない場合には、最初に入ってきたデータを削除したり、最近使用されていないデータを削除したり、あるいはこれ以上データを入力できないようにします。
最良の方法は、削除されたデータをRedisに任せず、自分で設定するということでしょう。当該データを入力するときに、このデータの使用期限がいつまでなのかを直接設定することで、アプリケーションがデータの使用有効期限を定めることができます。つまり、キーに対するtimeoutを設定します。設定されたtimeout時間が経過すると、キーのDELコマンドを呼び出したようにキーが自動的に削除されます。数秒後に削除されるなど残り時間の値を利用したり、あるいはUnixのtimestampを使って削除すべき時刻を設定することもできます。

NHN Cloud Meetup 編集部