Java ORM技術の標準スペックであるJPAが紹介されて随分経ちます。ただし、大規模システムに使われきたJPAの運営経験は十分に活用されていないように見受けられます。
JPAを使うとき、Hibernateが実装体として用いられることが多いようです。私たちが担当しているサービスでもSpring Data JPAを活用しており、JPAの実装ライブラリはHibernateを使っています。私たちが開発とサービスを運営しながら体験したことの中から、SQLのIN clause (IN句) に関して発生した問題の解決方法と、そこで学習したオプション、それによる効果について紹介したいと思います。
症状
- 運営中のサーバーがこれといった理由もなく応答が遅くなりました。また、ガベージコレクション(GC)をあまりにも頻繁に行っています。
- ヒープダンプをしてみると、Hibernateがメモリの60%以上を使用していました。JVMを起動する際、xmxを1024mに設定しましたが、現在は約650MBを使用しています。
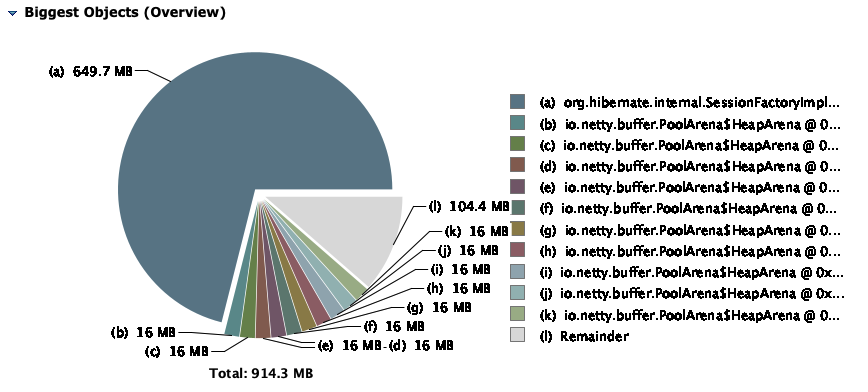
- さらにGCを強制してもヒープに余裕ができません。
- 結局、OutOfMemoryErrorが発生します。
原因
- 私たちはJPAを使う際、余分なJOINをせずにすむように、IN clauseを多く使用しています。
- 次のコードは、Spring Data JPAを適用したコードです。findByIdInメソッドの引数をListで処理すると、自動的にIN clauseに変更されます。
public interface SampleRepository extends CrudRepository<Sample, Integer>{
List<Sample> findByIdIn(List<Integer> ids);
}
select .... from Sample where id in (? ,? ,?)
- ところが、ここで問題があります。idsは固定されたサイズのオブジェクトではありません。大部分のクライアントが特定の個数を単位として呼び出しますが、常にその個数で落ちる呼び出しにはなっていないでしょう。
- たとえば、次の数をidsに割り当てて結果を得ようとします。
1,2,3,4,5,6,7,8,9,10,11,12
- 数字が過度に増えることに備え、5個ずつに切って呼び出すように開発したと仮定します。(もちろん、5個ずつに切るのは実務的ではありません。)
1,2,3,4,5
6,7,8,9,10
11,12
- このように繰り返しながら呼び出して、結果を得ることになるでしょう。
- このとき、処理されるSQLは次のように呼び出されます。続けて5個の引数でクエリをして、最後にIN clauseで2つの引数でクエリが発生します。
select .... from Sample where id in (? ,? ,?, ?, ?);
select .... from Sample where id in (? ,? ,? ,? ,?);
select .... from Sample where id in (? ,? );
- 次の呼び出しは、以下のidsを用います。
- たとえば、次の数をidsに割り当てます。(13を追加しました)
1,2,3,4,5,6,7,8,9,10,11,12,13
select .... from Sample where id in (? ,? ,?, ?, ?);
select .... from Sample where id in (? ,? ,? ,? ,?);
select .... from Sample where id in (? ,?, ?);
- このようにサーバーを運営すると、5種類のSQLが生成されて呼び出されます。
- 一般的にサーバー側ではクライアントは制御できません。
- 制限なく呼び出すと、呼び出す度に異なる種類のSQLが生成される確率が高くなります。
- これにより、データベースの観点からプリペアドステートメント(preparedStatement)効果が享受できなくなります。
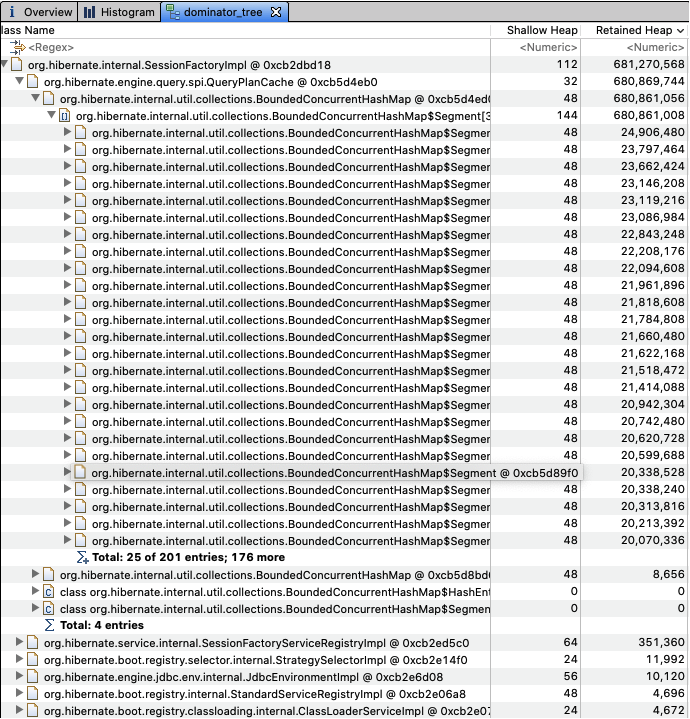
- より深刻な問題は、アプリケーションで、Hibernateは実行プランのキャッシュに種類別のクエリデータをロードすることになります。実行プランのキャッシュは、ヒープメモリを徐々に占有します。
- 私たちが経験した問題は、1000個単位でデータをフェッチ(fetch)してくることでしたが、データを1000個に切って長期間呼び出していると、1000個の異なるクエリの実行プランのキャッシュを発生させてしまうことになってしまいます。
解決方法
1)in_clause_parameter_paddingを設定する
- Hibernate ORM 5.2.18以降を使用している場合は、次のオプションを設定します。
<property>
name="hibernate.query.in_clause_parameter_padding"
value="true"
</property>
- もちろんSpringBootでは、次のようにapplication.propertiesに設定すればよいでしょう。
spring.jpa.properties.hibernate.query.in_clause_parameter_padding=true
1,2,3
1,2,3,4
1,2,3,4,5
1,2,3,4,5,6
- Vlad Mihalceaの説明によると、2のべき乗単位でパディング(Padding)します。オプションがなければ、異なる4つのSQLを呼び出しますが、ここでは2種類に留まっています。
select .... from Sample where id in (1 ,2 ,3, 3);
select .... from Sample where id in (1 ,2 ,3, 4);
select .... from Sample where id in (1 ,2 ,3, 4, 5, 5, 5, 5);
select .... from Sample where id in (1 ,2 ,3, 4, 5, 6, 6, 6);
- 1〜1000個の他のパラメータ数の呼び出しがあるとき、オプションがない場合は、1000個の他のSQLを生成しますが、上記のオプションを使った場合、わずか10種類のSQLが生成されます。
- こうなると、execution planを再利用できます。execution plan cacheがヒープをいっぱいにしてしまうという問題も解決されます。
この案がコードを変更せずに性能を向上させる良い方法だと思われます。
2)プログラムでパディングを制御する
- 文字通りパディングをプログラムで行うことです。
- このメソッドまたはサービスのクライアントが最大何個まで送信するか分からないため、パディング単位の処理を直接実装しなければならないという面倒さがあります。
- バッチアプリケーションのように、アプリケーション内でのみ呼び出してクライアントを自ら開発する場合には、最適の結果を作り出すことができます。
3)クエリプランキャッシュの最大サイズを調整
- 単にプランキャッシュのサイズを制限することもできます。
<property
name="hibernate.query.plan_cache_max_size"
value="2048"
/>
- 2048個はデフォルト値で、大半の小さなサイズ、中くらいのサイズのアプリケーションでは十分な値であると思われます。
- この十分な値がどのような場合で問題を引き起こすか、2048から減らしながらメモリの状況を見る必要があります。
- ネイティブクエリはparameter metadataを管理しますが、これもキャッシュの大きさを制限することができます。
<property
name="hibernate.query.plan_parameter_metadata_max_size"
value="128"
/>
参考リンク

